Introduction
Aggregate functions are a very powerful tool to analyze the data and gain useful business insights. The most commonly used SQL aggregate functions include SUM, MAX, MIN, COUNT and AVERAGE. Aggregators are very often used in conjunction with Grouping functions in order to summarize the data. In this story, I will show you how to use a combination of aggregate function and grouping functions.
Preparing some sample Data
Let’s parepare some sample data for this lesson using these scripts below. You can use different platforms of your choice, for instances SQL FIDDLE, KHAN ACADEMY etc.
CREATE TABLE Customer (id INTEGER , name TEXT, product TEXT, OwnershipPercentage numeric(4,3) , Effective_date numeric);
INSERT INTO Customer VALUES (1, “BankA”, “A01”, 0.028, 20180223) ;
INSERT INTO Customer VALUES (1, “BankA”,”A02”, 0.018, 20181224) ;
INSERT INTO Customer VALUES (2, “BankB”,”B01”, 0.025, 20190101) ;
INSERT INTO Customer VALUES (2, “BankB”,”B02”, 0.045, 20200101) ;
select * from Customer;
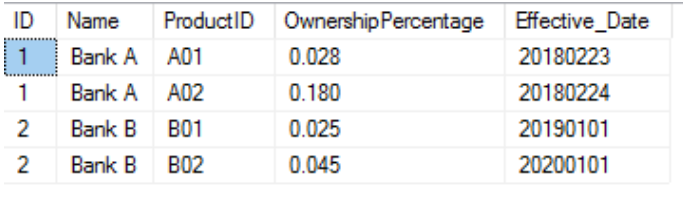 Table Customer
Table Customer
Problem
Now you see that for each customer, there are multiple (in this case, 2) records for OwnershipPercentage and effective dates with regard to different Products. Let’s say, I need to produce a report for my boss and want to do some data analytics to back my report up. Depending on what I want to see, I will use different aggregate functions. In this lesson, I will give examples using SUM() and MAX() functions. You can come up with different scenarios to play around with other functions.
Solution
I would, for instance, like to see how the portfolio has changed over time for each customer compared to the previous report. To do so, I want to see the total ownership percentage for each customer regardless of Product. There are two ways I can do this: using GROUP BY AND PARTITION BY
Using GROUPBY
Very simple, what I can do is using aggregate SUM() function following by a ‘GROUP BY’ Clause. In the query, SUM() function will adds up all the values in a numeric column (OwnershipPercentage). GROUP BY clause groups all identical values in columns which are the attributes we choose, in this case Customer ID and Name.
SELECT ID,
Name,
sum(p.ownershippercentage) AS onwership_percentage
FROM Customer GROUP BY ID, Name
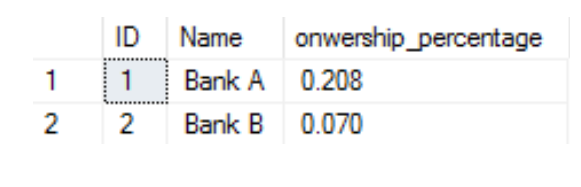 Result for Group by
Result for Group by
Using OVER and PARTITION(BY)
Another way to get somehow a similar result is using OVER and PARTITION(BY) function. To use the OVER and PARTITION BY clauses, you simply need to specify the column that you want your aggregated results to be partitioned by. The Over(partition by) clause will ask SQL to only add up the values inside each partition (Customer ID in this case).
SELECT ID,
Name,
ProductID,
OwnershipPercentage,
sum(OwnershipPercentage) over(partition by ID) as total_ownership_percentage
FROM Customer c
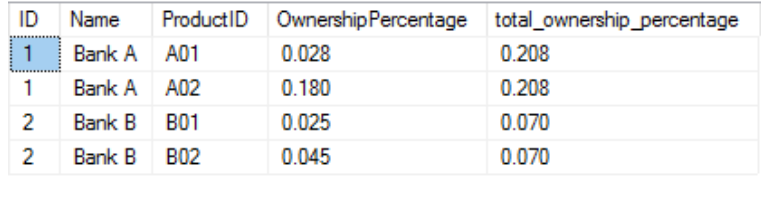 Result for Over(Partition by)
Result for Over(Partition by)
With the above query, I will get a column called total_ownership_percentage which is the total of owership percentage values for each customer.
Now you may have realized the differences between the output of GROUP BY and OVER(PARTITION BY). GROUP BY essentially reduces the number of returned records by rolling the data up using the attribute we specify. OVER(PARTITION BY) meanwhile provides rolled-up data without rolling up all the records. In this case, by using PARTITION BY, I will be able to return the OwnershipPercentage per given Product per Customer; and the total percentage per Customer in a same row. This would mean that I will have repeating data for the total OwnershipPercentage per Customer but the good thing is, no data has been lost during the aggregation — as opposed to the case with GROUP BY.
SELECT ID,Name,
p.OwnershipPercentage,
max(c.OwnershipPercentage) as ownership_percentage FROM Customer c GROUP BY ID,Name
Using the above code, I will receive this message: Column ‘Customer.OwnershipPercentage’ is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause. This is because GROUP BY will only return unique results per group and the SELECT list can only consist aggregate functions or columns that are part of the GROUP BY clause.
So depending on what you want to get, you can use different functions to get the optimal output. Go for GROUP BY when you need one unique record per group, and PARTITION BY would be the best opion when you do not want to lose any data but still want to do the aggregation.
Using aggregate MAX() and GROUP BY
Here is another scenario using MAX(). Let’s assume I now want to know the most recently added product and its OwnershipPercentage per Customer.
One solution for this is applying aggregate Max() function and GROUP BY in a sub-query. A sub-query is a SELECT Statement within another SQL Statement.
select c.Name,
c.ownershippercentage,
c.Effective_date as effective_date
from Customer c
inner join (
select Name,
max(Effective_date) as max_date
from Customer group by Name) d
on c.Name = d.Name
and c.Effective_date = d.max_date
The sub-query will return a table which I called “d”. With this sub-query, I get the latest Effective Date for each Customer in Table “d”. From that, I perform a JOIN between Table “Customer” and Table “d” to derive the OwnershipPercentage for that latest effective date. The above query will give you the desired output but is not the optimal solution. We had to use a JOIN statement and a combination of aggregate MAX() and GROUP BY in a sub-query which increases the complexity. Find below a more efficient code:
SELECT c.ID, c.Name, c.ProductID, c.OwnershipPercentage, c.Effective_Date
FROM Customer c
WHERE c.Effective_Date = (SELECT MAX(p.Effective_Date) FROM Customer p WHERE p.ID = C.ID)
Either way will give you the same result as below:
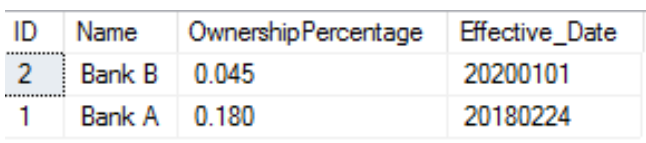
Thank you for reading. I hope this helps with learning.
Originally published on Towards Data Science